First Principles take on Nakamoto consensus in an eventually consistent decentralized network
The blog is deliberately titled in this way. Because I don't intend to describe the internal working of Bitcoin. It's there in the whitepaper, anybody can read that. What I aim to accomplish is something different.
Yes, we’re talking about Bitcoin. But Bitcoin in itself isn’t very exciting for me.
From the perspective of distributed systems, the thing that stands out to me is the Proof of Work (PoW) algorithm mentioned in the whitepaper.
The goal isn’t to talk about the internals of Bitcoin, blockchain or even the PoW algorithm itself.
The ultimate goal of this write-up is to hover around PoW in circles and use first principles to discuss solutions for differently-framed problems.
Those that aren’t mentioned in the whitepaper.
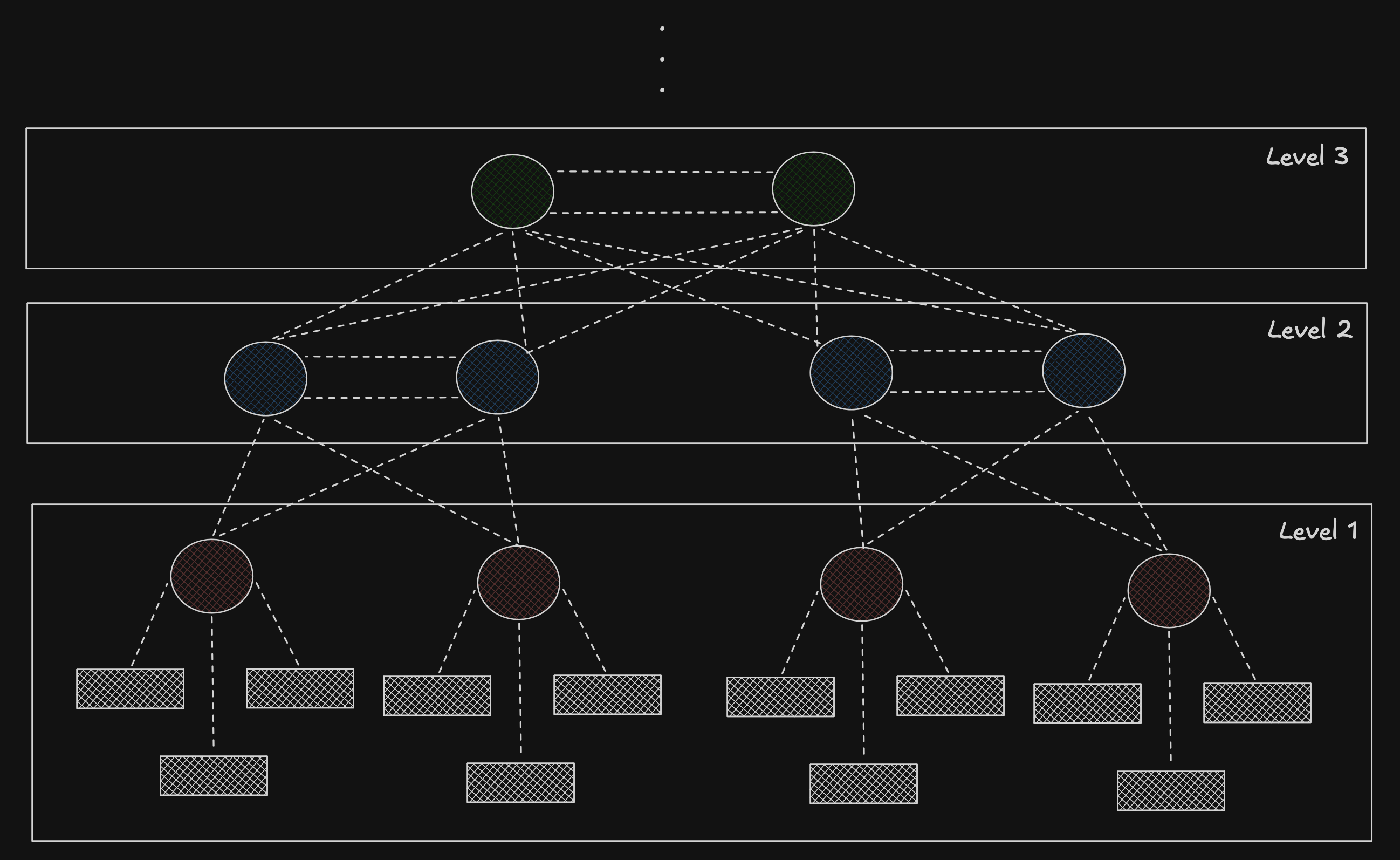
Hierarchical network topology setup
We have to start with Leslie Lamport’s foundational 1982 paper on the Byzantine Generals’ Problem.
It is actually a game theory (which I intend to formally study one day because it sounds so cool) dilemma but for us, it’s an issue to look at from the PoV of distributed computing.
He mathematically proved that in a distributed network using messages that are in complete control of the “sender”, you need more than two-thirds of the network to be honest to achieve consensus.
So: to tolerate F dishonest actors, a network requires at least 3F + 1 total participants.
But here’s where I am stuck. If you look very closely, Lamport’s proof assumes a flat, symmetric topology. It assumes every node is a first-class citizen (either honest or dishonest) meaning every node has an identical vote and every node is willing to accept the identity of another.
But what if we could flip the script and have a hybrid setup for nodes? What if we drop the constraint of a flat topology? Because this is exactly how the Internet works at L2/L3. It follows an asymmetrical topology.
And that individual nodes decide who they trust locally instead of blindly relying on a global pool.
Although there’s still economic interests involved (at the BGP level), it can lower the cryptographic complexity by a lot.
And as long as we can fund the newly-created decentralized network, just like we fund our own connection to the Internet, achieving this seems to have a pretty practical approach in my opinion.
 (I know there are many drawbacks of it that I can think of upfront. But I genuinely think if we add some constraints to it and re-frame the guardrails in a specific way that this would be a good rabbit hole to get into. Maybe this won't work out but it deserves an honest attempt from my end.)
(I know there are many drawbacks of it that I can think of upfront. But I genuinely think if we add some constraints to it and re-frame the guardrails in a specific way that this would be a good rabbit hole to get into. Maybe this won't work out but it deserves an honest attempt from my end.)And it’s absolutely exhilarating to know that my first principles intuition do lead somewhere. It’s validated by David Mazieres’ work on the Federated Byzantine Agreement (discovered this when I talked to an LLM about my ideas).
Instead of requiring a global identity system to establish a 3F+1 quorum, nodes declare their own Quorum Slices (local pools of trusted peers). When these slices overlap, global consensus emerges bottom-up. And in this way, you don't need to know everyone, you just need your trusted circles to intersect.
Although this is a rabbit hole to discover, I think I am pretty new to the field and that it’s better to cover a certain amount of breadth before dedicating myself into a specific niche.
PoW is an artificial clock capable of producing universal ticks
Time in itself is a distributed problem is something Claude told me during one of our coffee chats.
Although this reminds me of how Spanner does it so well by utilizing GPS receivers for mere databases, I think we should stick to the point.
If you zoom out a little and focus instead on the specific semantics of how the blockchain works, you would agree with my take.
There’s this very famous 1978 paper by Leslie Lamport (Time, Clocks, and the Ordering of Events in a Distributed System") and it proved that because of network latency and relativity, you cannot have a perfectly synchronized global physical clock. You can only track a partial order of events (what happened before what).
Now think of the hashing process as an accumulation of universal uncertainty.
Uncertainty of which node will produce a result that could progress the entire system forward.
This combined with other nodes fighting for the same spot can be considered as entropy. But when a miner finds a block, the uncertainty violently collapses.
Although it still sustains itself for a short amount of time (as described in the paper in a different way). And since the nodes accept a certain block using a trivial proof-checking mechanism, it can be viewed as a beautiful scene of all nodes coming together to produce (or accept) a universal tick of a clock across the whole planet.
Sadly it happens every 10 minutes, but still.
You should use an adaptive algorithm to achieve consensus without ordering
I know I'm pretty ambitious right? But I can convince you and I can do within this section itself.
Although yes it's a bit of a clickbait because there are some constraints to it.
Well reading about TigerBeetle and Bitcoin got me a little curious about the finance domain in distributed systems. In one of my classes at university, we were told by our professors that a lot of real-life events and situations are connected with the computing world.
And it kind of makes sense. When you start to go deep into a field, you see the same abstractions being repeated elsewhere.
Using first principles, let’s devise why we are even going down this route. Let’s assume I went to the bank to deposit $10 to your account. Done. Now at the very same time, you went to the same bank to deposit $5 to your account. Nice.
You see, ordering is not even required here and that’s purely due to the fact that addition is commutative.
In distributed systems, we call this a Conflict-free Replicated Data Type (CRDT). It is a data structure designed so that concurrent updates can be applied in any random order across different nodes, and they will always naturally converge to the exact same truth without a leader or a voting round.
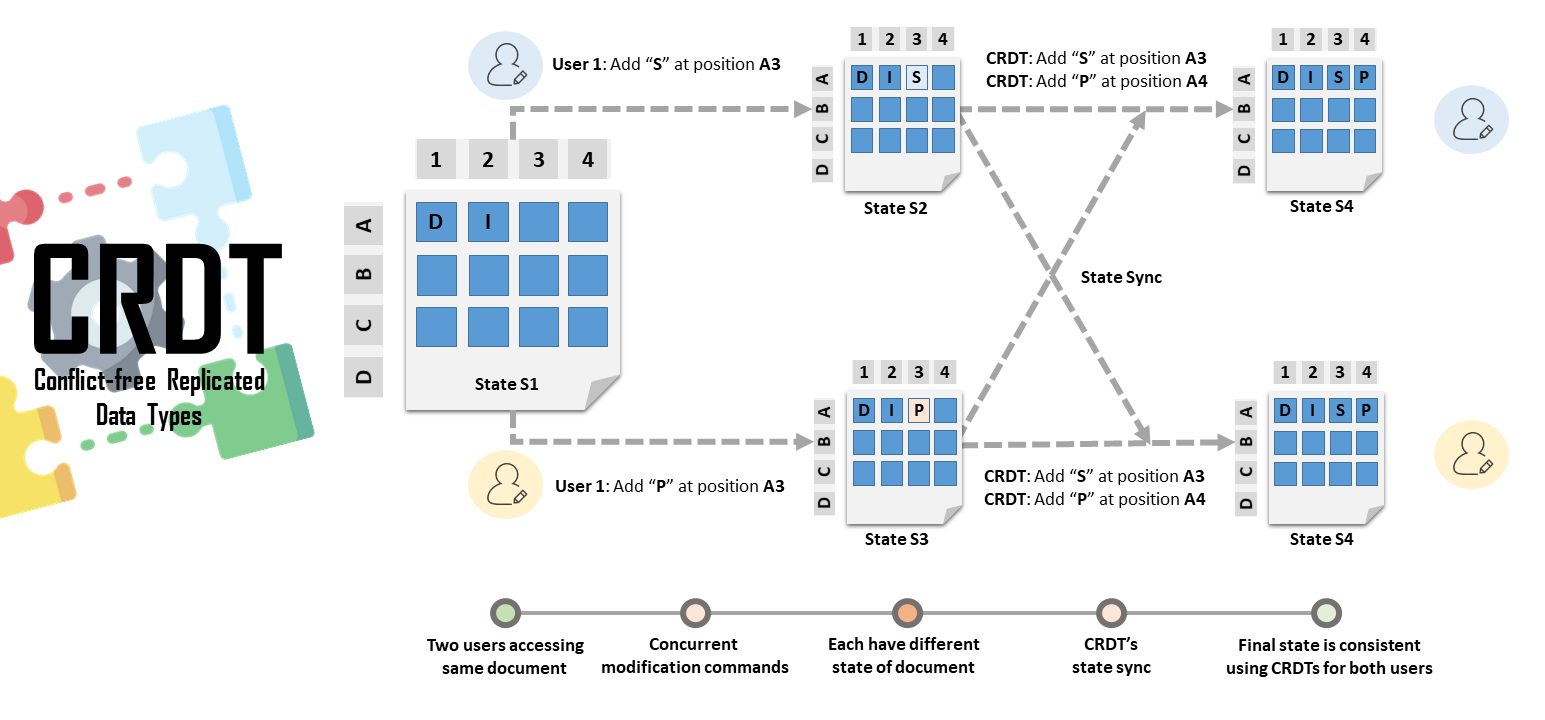 (A high-level overview on CRDT. Image taken from Google.)
(A high-level overview on CRDT. Image taken from Google.)Let’s take another example. Suppose you buy a show ticket in New York and I buy the same ticket from Delhi.
There’s just one problem: there only remains one ticket now. In this specific case, ordering is absolutely necessary or it will cause split-brain situations.
And through this, I intend to make you realise we shouldn't treat all database operations equally. In essence, an intelligent and adaptive consensus algorithm can be created that operates on two different paths.
One that’s fast and does not require an ordering and one that does perform the traditional form of consensus.
Now, if you think I am just spitballing some ambitious, hypothetical dream here, I am not.
The distributed systems community has been quietly obsessing over this exact "fast path / slow path" dichotomy for years.
You should absolutely read the 2020 paper called "FastPay: High-Throughput Cryptographic Settlement”. Same basic idea but obviously far more depth than I have as of now.
A lot of people have told me this before: ”oh you’re lying to your teeth, you couldn’t have done this without an LLM”.
And it’s sad because had I got a PhD degree to my name, nobody would’ve questioned my thoughts. The fun fact is that it’s not even anything research-based.
I just attempt to look at the system from a different PoV, that’s it. I don’t even go further because I don’t have the depth yet.
But it’s fine. I guess some people cannot even fathom having their own thought process and mental models without external help.
I do hope that these month-long journeys of dissecting papers to build my own mental models pays off in the long run.