A fresh look at the design primitives of deterministic consensus algorithms
This is me trying to look at a particular consensus algorithm with a 0.0001x lens but thinking about it in general terms. The only reason I am doing this is because I hope to build my own sensational consensus algorithm one day (a little ambitious I know).
The reason I use the word “unconventional” is because we’re not going to go down the average route of understanding the implementation details.
Raft is an example using which I’ll describe my case. And it is one of those whitepapers that I have high regards for, purely due to the fact that it explains the internals so well. It deserves respect for that.
In the world of distributed systems, every decision is a trade-off. And the fact that Raft was modelled to be “understandable”, it kills me to think that there are a lot of gains we’re leaving on the table.
The upcoming dissection is not purely based on Raft but it’s hard to describe anything without using examples.
So, shall we?
Dynamically buffered writes for spiky workloads in multi-tenant systems
One of the problems that Raft experiences is serialization even under periods of heavy write queries.
It creates major performance bottlenecks which the paper does not describe. Raft performs a full-blown consensus once per every write (or read but let’s ignore that).
And that brings me to the question: “What might be some solutions in case my system has spiky workloads like batch jobs running at 4AM?”
Well, this type of solution obviously requires buffered writes. Which means application changes. More than that, it would be extremely tailored to my business requirement. Or maybe using feature flags living on an in-memory cache.
But then, immediately my mind goes: “What if I don’t know about the workload? What if my business requirements enforce multi-tenancy?” And that’s an interesting problem to solve.
Although I am pretty sure there are some good solutions out there. I want to perform some first principles thinking here. And that I will look at this problem statement later (when I have accumulated a little more knowledge).
I read this paper co-authored by a very popular content creator (and an engineer) in the Indian tech community: Arpit Bhayani.
His paper “Cold-RL” basically describes integrating a Deep Q-Network (DQN) into NGINX for cache eviction.
Two things that stood out:
(1) the model was fully-offline → trained entirely on historical access logs
(2) RL model sidecar took longer than 500 microseconds to think → the system immediately killed the request and fell back to standard, deterministic LRU.
If we port over his ideas onto our problem statement, it would make for a very sweet solution.
The way it would work is that the Leader would operate like it normally does, just with the difference that there’s a buffer that the Leader temporarily stores its writes in.
Our RL model (I’ll be honest I am not deep into RL/ML stuff, so let’s assume it as a black box) tweaks the buffer size based on the workload pattern.
If the spike is massive, so is the throughput because now we can pack tons of writes together, but obviously latency suffers a bit.
If the workload is steady/low throughput, the Leader gets choked by serialization overhead but the latency is low as well.
And as for the fallback, if the RL model hasn't emitted an optimal batch window size within 100 microseconds, the system completely ignores it and falls back to a classic heuristic like a fixed 5ms slide window.
I know this is easier said than done.
I am pretty sure I am overlooking a lot of sub-problems but at a high level, it does look a bit promising to be honest.
But again, I cannot say anything with certainty unless I have banged my head on the problem multiple times and researched enough.
What’s the starting point of designing a consensus algorithm from scratch?
The recipe for it is simple and it’s not. But as a non-researcher, we can at least gain some high-level understanding of a common pattern.
The most important part is deciding two factors: (1) how strong is your ordering and (2) how strong is your execution? These two knobs have the power to decide the liveness and safety guarantees for your consensus algorithm.
Let me take some examples:
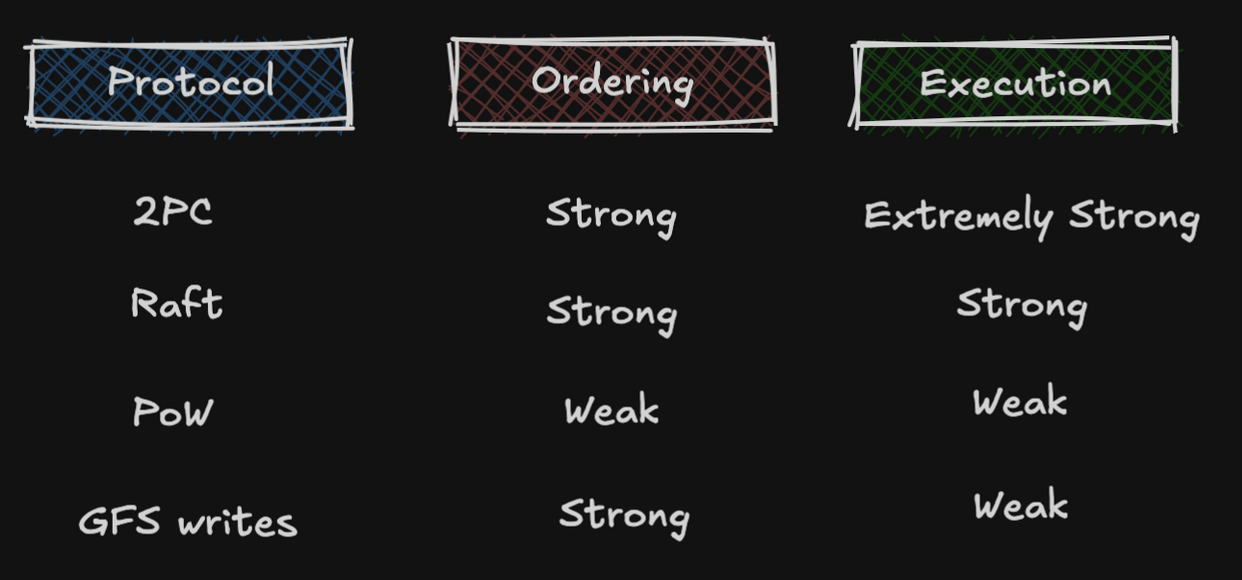 (The table that lines up sadly not too many ordering+execution algorithms to showcase the knobs for liveness v/s safety.)
(The table that lines up sadly not too many ordering+execution algorithms to showcase the knobs for liveness v/s safety.)Explaining GFS writes would be the best way to gain an insight into this table.
The way writes work on a GFS chunkservers (CS), assuming a primary CS and two secondary CSs: Primary CS serializes the writes and orders the secondary CSs to do the same. Once that’s done, they’re expected to execute the writes on themselves.
But it’s a distributed system :) Things are supposed to crash and let’s assume they did.
So one of the secondary CSs goes down. When that happens, the way GFS is modelled, it considers the entire operation to be a failure.
Instead of rolling back on the primary and the other secondary CS, it just sends back a failure to the client. The client then re-attempts the operation.
In this way, although the ordering was strong, the execution was a bit weaker. And in this way, it traded some safety for the liveness guarantee.
Similar case for Raft. During ordering, it serializes the writes pretty strongly. But during execution, it only needs a majority quorum to send an ACK back to the client (aka commit to the client).
On top of that, if things go sideways, there exists a backtracking mechanism which means the entire system remains strongly consistent and promotes safety over liveness which is exactly the point I was trying to make.
And although this is a very small sample set, I am pretty sure it’s a good starting recipe of how your consensus algorithm should look and mature.
Another important aspect that I’ve seen a lot: network topology. Read below.
Flat network topology
Time and again, I have encountered the role of topologies in consensus algorithms. I mean generally they all consider a flat network topology and it kills me to think what might be the throughput and performance under different types of network topology.
I was reading this Cockroach DB blog where they talked about "Multi-Raft". And that’s because scaling Raft is actually hard.
First off, as the system grows, so does the amount of traffic required to handle heartbeats.
Second, at some point your cluster is so large that your latency starts to suffer purely due to the fact that achieving consensus among so many machines takes time. This is something I am definitely going to explore.
I had a tree-like network topology in mind, but that’s literally it. I need to give some time to this.
Raft is just 2PC in disguise
The dreaded two phase commit protocol. Yes, Raft is just that. I mean it’s slightly more superior but the fundamental mechanics of them both are pretty much the same.
What do the mechanics of 2PC suggest? It has two rounds. And the consistency it tries to achieve, the two rounds are absolutely necessary.
The first phase aka “PREPARE” phase asks the participants to store a particular transaction and if and only if the coordinator receives a YES from all the nodes, does it actually proceed to the next phase. The next phase being the “COMMIT” phase.
Also the most dreaded stage. If the coordinator sends out a request to even one participant, it has to bring back home a victory no matter what.
If the system has to wait indefinitely, so be it.
 (Putting into image how they actually don't differ much.)
(Putting into image how they actually don't differ much.)And so as I am describing this protocol, it becomes pretty clear. The transaction coordinator is a Leader.
The participants are followers. And that there exists two phases within Raft too.
First one being an AppendEntries RPC that has the new entries.
Second being the same AppendEntries RPC but with the new leaderCommit integer.
And there’s still the dreaded stage here but since Raft is attempting to achieve something entirely different than 2PC, it can easily mitigate this using the quorum property.
Technically even when the node remains down, the Leader keeps hammering it with the information by piggybacking it in every single heartbeat until the node gets back up.
So that’s my observation. And given that, it’s sad to say how much we criticize 2PC but praise Raft even when they’re born out of the same mother.
Now obviously the goal they’re trying to achieve is extremely different, but still.
And yep. That's all from my side. I know there might be several gaps in knowledge and a lot of things that the frontier is doing at this moment of time in distributed systems.
One of my approaches of doing first principles serve me well but then I feel it also stops me from truly discovering the beauty of frontier systems.
Because when I should be focusing on dissecting each and every part of modern systems (even classical), I feel much more fulfilled when I try to come up with the solutions suggested in the paper using first principles.
By looking at the problem statements and given a set of constraints, it brings me joy to do that. But maybe I need to change that now.